正则表达式阶段性记录
昨天在写一个diff脚本的时候,需要过滤#开头的注释,以及过滤掉过滤#后出现的空行,Google后我的脚本变成了grep -v '^#' | grep -v '^$' 这样,可用但是并太不明白^$的意思,猜测可能是开始即结束?
因为我尝试加上几个空格匹配会失败,且改成 grep -v '^#'|grep -Ev '^\s+$' 是可以的,今天又搜了下想确认猜测,然而并没有找到相关的说明,但是也有其他收获。
首先是梳理了下正则的各种分支和规范,比如POSIX、Perl、RE2等以及包含的子集。
其次是匹配包括换行的写法,以前在写PHP的时候比较习惯使用flag,比如i、s、U这些,现在又多了几种写法:[\s\S]*、[\d\D]*、[\w\W]*、[\v\V]*、[\h\H]*。
是不是挺迷惑,我一开始也是,那现在再来回顾下语法:
\d 数字,[0-9]
\D 非数字,[^0-9]
\s 白空格,[\t\n\f\r ]
\S 非白空格,[^\t\n\f\r ]
\w 整个单词,[0-9A-Za-z_]
\W 非整个单词,[^0-9A-Za-z_]
\h 水平空格
\H 非水平空格
\v 垂直空格
\V 非垂直空格以 [\d\D]* 来说(其他都一样)数字和非数字,可不就是包括了全部字符嘛。
最后这个感觉最新奇,匹配所有的英文:[ -~]* 和非英文:[^ -~]*,是不是更迷惑了?再看看,想一想 [a-zA-Z0-9] 是不是就有点感觉了,所以这两种写法是匹配Ascii表中从空格 到波浪号~范围内的全部字符,借用一张图:
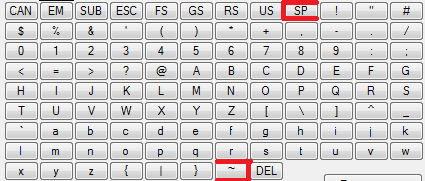
对这个的中文描述是:可打印字符,包含了可见字符和空格,即:图形字符、数字、标点符号、空格,正则对Ascii字符的分组可以看参考连接的最后一个,或者 从 Golang 正则式讲起的 3.10 章节。
PS:
额外提一下,GoLang的正则也支持设置flags,写法实例:regexp.Compile(\`(?is)([a-z]+)\`),注意这里是使用的反引号。
参考:
POSIX正则表达式
正则表达式匹配任意字符(包括换行符)的写法
在线正则表达式测试
从 Golang 正则式讲起
Regular expression for all printable characters in JavaScript
Character-Classes-and-Bracket-Expressions